At BetaNYC, we have been working on a tool to map vacant storefronts in Manhattan. Since there is currently no city entity comprehensively tracking the location or status of vacant storefronts across the city, we are attempting to reverse engineer this data by mapping where there are commercial units in the city and then removing from that map units that we know to be hosting a commercial business. One component of this effort has involved identifying Manhattan businesses with current active permits or licenses. In some cases, this is simple. The Department of Consumer Affairs publishes a dataset on NYC’s open data portal called Legally Operating Businesses, which lists the name, address, BBL, and permit status of all businesses licensed through the DCA. It is a great dataset – updated daily and rich in geographic units. However, not every business in NYC is required to get a license through the DCA. Here is a list of industries that do:
| Amusement Arcade | Garage and Parking Lot | Retail Laundry |
| Amusement Device – Permanent | General Vendor | Scale Dealer/Repairer |
| Amusement Device – Portable | General Vendor Distributor | Scrap Metal Processor |
| Amusement Device – Temporary | Home Improvement Contractor | Secondhand Dealer Auto |
| Auction House | Home Improvement Salesperson | Secondhand Dealer General |
| Auctioneer | Horse Drawn Cab Driver | Sidewalk Café |
| Bingo Game Operator | Horse Drawn Cab Owner | Sightseeing Bus |
| Booting Company | Industrial Laundry | Sightseeing Guide |
| Car Wash | Industrial Laundry Delivery | Special Sale (e.g., Going Out of Business, Liquidation, etc.) |
| Commercial Lessor | Locksmith | Stoop Line Stand |
| Dealer in Products for the Disabled | Locksmith Apprentice | Storage Warehouse |
| Debt Collection Agency | Newsstand | Temporary Street Fair Vendor Permit |
| Electronic & Home Appliance Service Dealer | Parking Lot | Ticket Seller Business |
| Electronic Cigarette Retail Dealer | Pawnbroker | Ticket Seller Individual |
| Electronics Store | Pedicab Business | Tobacco Retail Dealer |
| Employment Agency | Pedicab Driver | Tow Truck Company |
| Games of Chance | Pool or Billiard Room | Tow Truck Driver |
| Gaming Café | Process Server Individual | Tow Truck Exemption |
| Garage | Process Serving Agency |
Some notable industries not included in this list are:
- Food service establishments (which are licensed through DOHMH)
- Pharmacies (which are licensed at the state-level)
- Clothing, shoe, book, and furniture retail (unless they deal second-hand goods)
- Barbershops and Beauty Salons (which are licensed at the state-level)
This blog post will focus on how we acquired data about Manhattan’s barbershops and beauty salons.
Barbershops and beauty salons are licensed through the New York State Department of Licensing Services. The state defines barbering as:
…shaving or trimming the beard or cutting the hair of humans; giving facial or scalp massage with oils, creams, lotions or other preparations, either by hand or mechanical appliances; singeing, shampooing, arranging, dressing or dyeing the hair or applying hair tonic; applying cosmetic preparations, antiseptics, powders, oils, clays or lotions to scalp, face or neck.
Beauty salons are referred to at the state-level as “appearance enhancement businesses” and include any establishment that provides a service of cosmetology, esthetics, nail specialty, natural hair styling, and/or waxing.
To own, control, or operate either of these businesses, an operator needs to obtain a license through the state, demonstrating that they comply with federal and regional health and safety laws. The operator also must operate the business at the address listed on the license. Businesses are required to renew their licenses every four years and must notify the state if the address of their shop changes or if the business closes down.
It is possible to search for Barbershops and Appearance Enhancement Businesses holding licenses through a NYS license look-up portal. In fact, at this Web address, I can fill out a Web form to request all Appearance Enhancement Businesses located in the city of New York, as well as all Barbershops located in the city of New York. When I run these searches, a grid of 10 entries appears listing each licensed business – its license number, license holder, business name, license status, issuance date, and expiration date.
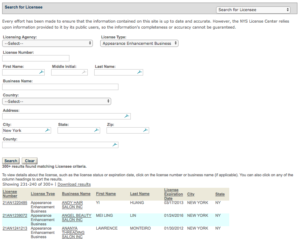
If I click through on any entry, I can also get the business’s address.
To get to entries beyond the first 10 entries, I can click on page numbers listed at the bottom of the page.
![]()
At the top of this grid, there is a link to “Download results.” However, the business’s address is not included in the results that download by clicking on this link. To get the names, addresses, and license statuses of all Appearance Enhancement Businesses and Barbershops in New York City, we need to scrape the results from the page.
Scraping the New York State license portal is more complicated than simply writing a script to access a URL and grab certain categories of data from the HTML file at that URL. You’ll notice that after submitting the page’s form or after clicking on a link to a new page of results, the results rendered on the page change, but the page’s URL does not change. There is no unique URL to show the results about just New York City or about just Barbershops, and there is no unique URL to get to page 2 of the results, or page 30, or page 500. The only way to access those specific results is to navigate to the license portal and manually click through to those results.
This is because NYS’s license portal is an ASP.net page. None of the data is listed in the HTML of the page; instead, each time a user fills out the portal’s Web form or clicks on a link, the page uses javascript to make a server request that the requested data be dynamically displayed on the page. This means that, in order to access those results, I needed to build a Python script that mimicked a user’s interaction with the page. In other words, I needed to build a script that mimicked filling out the Web form, clicking through to each license that displays on the page, and clicking on each page number following the first.
This can be done using Selenium – a Python package that enables a script to initiate a “headless” Web browser, or in other words, a Web browser without a user interface. Using Selenium, it is possible to write a script that opens a headless browser, navigates to a URL, fills out and submits a form at that URL, clicks through to links that get rendered dynamically, and scrapes data on resulting pages. I learned how to build this scraper based on a blog post written in May 2018 by Todd Hayton, a freelance software developer. In the post, Hayton described how to use Selenium to scrape a page structured very similar to the NYS license portal. Here is the basic logic of the script:
First the script opens a Selenium Web browser, and navigates to https://aca.licensecenter.ny.gov/aca/GeneralProperty/PropertyLookUp.aspx?isLicensee=Y. Then the script selects ‘Appearance Enhancement Business’ from the dropdown, fills ‘New York’ into the City field, and submits the form. At this point, the first 10 results should be loaded within the headless browser.
class LicenseScraper(object):
def __init__(self):
options = Options()
options.add_argument("--headless")
self.url = "https://aca.licensecenter.ny.gov/aca/GeneralProperty/PropertyLookUp.aspx?isLicensee=Y"
self.driver = webdriver.Firefox(firefox_options=options)
self.driver.set_window_size(1120, 550)
def scrape(self):
self.driver.get(self.url)
# Select license type from dropdown; this one selects "Appearance Enhancement Business"
selectLicense = Select(self.driver.find_element_by_id('ctl00_PlaceHolderMain_refLicenseeSearchForm_ddlLicenseType'))
selectLicense.select_by_index(4)
# Input New York as City
inputCity = self.driver.find_element_by_id('ctl00_PlaceHolderMain_refLicenseeSearchForm_txtCity')
inputCity.send_keys('New York')
self.driver.find_element_by_id('ctl00_PlaceHolderMain_btnNewSearch').click()
# Wait for results to finish loading
wait = WebDriverWait(self.driver, 10)
wait.until(lambda driver: driver.find_element_by_id('divGlobalLoading').is_displayed() == False)
self.driver.save_screenshot('screenie.png') #If you'd like to check results
From here, I needed to navigate to the link for each of these 10 license entries, scrape the data listed on the license’s unique page, and write this data as a row in a CSV file. Notably, however, the URL to each license is not listed in the page’s HTML. Instead when the user clicks on a license number, the ASP.net page sends a request to the Web server to load the data for the clicked on license. In doing so, it dynamically generates the URL for that license as https://aca.licensecenter.ny.gov/aca/GeneralProperty/LicenseeDetail.aspx?LicenseeNumber=[LICENSENUBMER]
The script creates this URL by finding all of the links with the ‘lnkLicenseRefNumber’ id on the page, extracting the text of that link, and then tacking that onto the end of https://aca.licensecenter.ny.gov/aca/GeneralProperty/LicenseeDetail.aspx?LicenseeNumber=. The script then uses the Requests library to access the link and Beautiful Soup to parse the text on the resulting page. It stores each piece of relevant data (including things like license number, business name, address, and license status) on the page into a separate variable, and then adds all of these variables as a row in a CSV file. It does this for each of the 10 entries listed on the first page of results.
while True:
s = BeautifulSoup(self.driver.page_source, 'html.parser') #parse the page
for a in s.findAll(id=re.compile(r'lnkLicenseRefNumber$')):
License = a.text
LicenseLink = License.replace(" ","%20")
LicenseURL = "https://aca.licensecenter.ny.gov/aca/GeneralProperty/LicenseeDetail.aspx?LicenseeNumber=" + LicenseLink #follow the link to the license
print LicenseURL
LicenseRequest = requests.get(LicenseURL)
LicenseSoup = BeautifulSoup(LicenseRequest.text)
LicenseNumber = LicenseSoup.find(id="ctl00_PlaceHolderMain_licenseeGeneralInfo_lblLicenseeNumber_value")
LicenseName = LicenseSoup.find(id="ctl00_PlaceHolderMain_licenseeGeneralInfo_lblContactName_value")
BusinessName = LicenseSoup.find(id="ctl00_PlaceHolderMain_licenseeGeneralInfo_lblLicenseeBusinessName_value")
LicenseAddress = LicenseSoup.find(id="ctl00_PlaceHolderMain_licenseeGeneralInfo_lblLicenseeAddress_value")
LicenseCounty = LicenseSoup.find(id="ctl00_PlaceHolderMain_licenseeGeneralInfo_lblLicenseeTitle_value")
LicenseIssue = LicenseSoup.find(id="ctl00_PlaceHolderMain_licenseeGeneralInfo_lblLicenseIssueDate_value")
LicenseEffective = LicenseSoup.find(id="ctl00_PlaceHolderMain_licenseeGeneralInfo_lblBusinessExpirationDate_value")
LicenseExpiration = LicenseSoup.find(id="ctl00_PlaceHolderMain_licenseeGeneralInfo_lblExpirationDate_value")
LicenseStatus = LicenseSoup.find(id="ctl00_PlaceHolderMain_licenseeGeneralInfo_lblBusinessName2_value")
f.writerow([LicenseNumber.text.encode('utf-8'), LicenseName.text.replace(u'\xa0', " ").encode('utf-8'), BusinessName.text.encode('utf-8'), LicenseAddress.text.replace(u'\xa0', " ").encode('utf-8'), LicenseCounty.text.encode('utf-8'), LicenseIssue.text.encode('utf-8'), LicenseEffective.text.encode('utf-8'), LicenseExpiration.text.encode('utf-8'), LicenseStatus.text.encode('utf-8')])
Then I needed to repeat this process for every page of results. Pagination is also quite tricky with an ASP.net page because again, there is no distinct URL for the “next” page, the 5th page, or the 300th page. Each of these pages has the same URL. Different results appear on each page because, when a user clicks on a page number, javascript tells the Web server which results to display on that page.
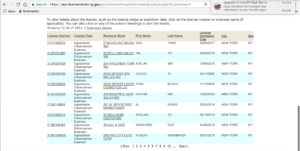
To render the next page’s results, I needed to find the link to the next page on the current page and tell the script to click on that link. The script does this by creating a variable called pageno, set originally to “2” – the number of the first “next page.” After scraping the first page’s results, the script looks for a link on the page with the same text as the pageno variable – in this case “2.” It clicks on this link and then waits for the next page to load. It knows that the next page is fully loaded by checking when the pageno link changes from an <a> tag to a <span> tag. Notably, the NYS license portal can be quite slow, so I set the code to allow for a full minute for this page to load. Then the pageno increases by one, and the whole script is repeated on the second page.
This took me through the first 10 pages of results (each with 10 entries); after this, the text of the link to the next page – “11” – does not appear on the page. Instead I needed to tell the script to click the “Next >” button, moving to the 11th page and loading the next 10 pagination links. The script repeats this until there are no more “Next >” pages.
# Pagination
try:
next_page_elem = self.driver.find_element_by_xpath("//a[text()='%d']" % pageno)
except NoSuchElementException:
try:
next_page_elem = self.driver.find_element_by_xpath("//a[text()='Next >']")
except NoSuchElementException:
break # no more pages
print 'page ', pageno, '\n'
next_page_elem.click()
def next_page(driver):
selected = driver.find_element_by_xpath("//span[text()='%d']" % pageno).get_attribute('class')
return 'SelectedPageButton' in selected
wait = WebDriverWait(self.driver, 60)
wait.until(next_page)
pageno += 1
There were over 5000 entries for New York City Appearance Enhancement Businesses – meaning that there were over 500 pages of results, and over 50 times the script needed to click on the “Next >” button to get the next set of pagination links. The first time I ran the code, it timed out after collecting about 1500 entries, and unfortunately, because of the design of the page, there is no way to ask the scraper to skip to page 150 to start the collection there. Because the content is loaded as a result of a server request, there is no URL for page 150, and when the scraper first displays results, there is not a link to page 150 on the page that loads. The only way to get to page 150 is to click through on the “Next >” button 15 times.
I really did not want to have to recollect all of the information already collected (at the chance that it might time-out again), so I created a small script (commented out in the current code) to designate the number of a start page, and then to click “Next >” until that number appears in the text of a pagination link on the page. Once that link text appears on the page, the original script kicks in collecting from the start page rounded down to the nearest 10. Then I appended the results from the second time I run script to the end of the CSV file that was created when I first ran the script, deleting the overlapping entries.
Once I had the CSV file downloaded, I geocoded each address using NYC Department of City Planning’s batch geocoding application, and the results of this scraping can now be found at data.beta.nyc:
Manhattan Licensed Barbershops as of May 2018
Manhattan Licensed Appearance Enhancement Businesses as of May 2018
Here is a link to the complete script: https://github.com/BetaNYC/Map-Vacant-Storefront/blob/master/Scripts/NYSLicensesSelenium.py
If anyone from the BetaNYC community has feedback on how to improve this script, I would love to hear it. Further, if anyone has leads on how we can get data about licensed pharmacies (at the city or state level) and/or about clothing, shoe, book and/or furniture retail stores (including addresses and BBLs), please email me at lindsay@beta.nyc.